C/C++软件逆向技术 分析定位目标功能:(第一天) 设置一下Debug:如下
设置一下Release:如下
对如下代码生成不同版本的exe:
1 2 3 4 5 6 #include <stdio.h> int main () printf ("hello Re" ); return 0 ; }
将debug版本的直接脱入ida:
拖入成功后。
它会给你三种选项,如下:
让你选择以某一种方式对他进行解析:
第一种方式:pe文件的方式对你的文件进行解析
第二种方式:是利用dos的形式对它进行解析
第三种方式:是利用二进制文本的方式对它进行解析,想怎么解就怎么解
这里我们已经知道是pe的可以直接选择第一种。
下面这个是可以简单选择一些架构的:我们选择metapoc
加载完毕后来到这个:这个页面:
我们可以通过如下方法来定位一手主函数main:
第一种方式:通过字符串来找 我们直接ctrl+f进行一下搜索:
然后双击点进去:
会发现有个名字这个是ida自动给你取的。
然后点击这个名字以后按下ctrl+x它会弹出一个交叉引用:(这里我是用的本机的ida7.7才弹出的)
这个所谓的交叉引用呢?就是你的这个字符串在全局内被调用了多少次,在哪被调用的,观察上图我们可以发现上图只有被调用了一次点击以后,选择ok。
ida9中可以右键点击:如下选择也可弹出:
观察上图我们可以发现上图只有被调用了一次点击以后,选择ok。
ok以后就跳到如下界面了,如下界面也就是我们的main函数:
接下来呢我们可以按空格把他切换到文本模式,也可以再按空格切换回流程图模式,如下:
也可以直接按F5把他转换成伪代码的形式:如下
第二种方式:根据一定规则来确定 假设我们已经知道了其对应的生成规则:然后重新生成一个demo.。
然后一层一层网上找,尝试了解他的main函数是如何找到的
我们直接右键,选择交叉引用,找它的上一级调用:如下:
有一个 jmp main,我们跳过去:如下
这层是只有一个 jmp _main跳过去的:
确定第1层: jmp _main
接下来我们直接:右键查看上一层:如下
我们会发现它传入了3个参数:
然后我们观察会发现他是这3个call里面的最后一个call
于是乎我们可以记录如下特征:
1 2 3 mov ecx, [eax] push ecx ; argc call _main_0
也可以记录进最后一个call
确定第2层:上面记录的就是第二层的特征
接下来我们继续进入上一层:
还是右键进入同上一样的操作:如下
我们可以将这几行作为一个特征:如下
1 2 3 4 5 6 7 8 9 10 经过整理:如下所示即为这一层的特征 movzx test jz mov mov push call add call
确定第3层 :如上特征
接下来我们继续往上找,找到这里的函数头:
找到其函数头然后进入上一层:如下
发现如下特征:
1 2 3 call call 然后我们可以记录一下特征是第二个call
确定第4层 :特征如上
接下来我们继续向上找看看还有没有上一层:
找到函数头,然后进入上一层:如下:
进入后如下
这一层就1个call:
直接记录就对了:
确定第5层 :如上。
再继续向上一层:
这一层呢是一个jmp,并且jmp这一层呢已经到start了,说明已经到头了
特征:
确定第6层
根据上述流程我们倒着把他记录了下来。
接下来我们根据上述流程正着进这个main函数。
利用x64dbg 来进行一下动态调试:
一打开我们就来到了:ntdll.dll模块下,如下:
直接F9跳入到我自己的程序临空:如下:
进入以后我就可以掏出我自己的规则:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 X86 Debug: 1.jmp main 2.进入最后一个call 3. movzx test jz mov mov push call add call 4.第二个call 5.call 6.jmp 倒过来就是正向的进入main规则了
直接F8 jmp进入 入口点:如下:
进入以后这里就一个call我们直接:F8下一步到call上以后直接F7跟进这个call
跟进以后可以看到如下内容:如下图:
根据规则我们需要进入第二个call :F8 F8 F7跟进:如下图:
然后根据下一个规则:
找如下特征:
1 2 3 4 5 6 7 8 9 10 3. movzx test jz mov mov push call add call
找到如下特征以后:F2下个断点:如下:
然后F9运行到此:然后F2取消断点:如下:
然后继续F7跟进:如下:
然后继续根据规则:进入最后一个call:
F2下个断点然后F9运行到这,以后F2取消断点:如下:
F7跟进去:如下:
然后我们直接F8jmp:可以成功看到我们的main函数:如下:
上述的就是X86 Debug的一个根据结果倒过来找路线的全过程。
然后可以自己调试一下前面生成的x64 debug
过程我忽略一下:直接找到如下规则:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 x64 debug: 第一层: main_0 proc near jmp main main_0 endp 第二层: 最后一个call 第三层: call j___scrt_is_nonwritable_in_current_image movzx eax, al test eax, eax jz short loc_140067DE9 mov rax, [rsp+68h+var_30] mov rcx, [rax] ; Callback call j__register_thread_local_exe_atexit_callback call ?invoke_main@@YAHXZ ; invoke_main(void) mov [rsp+68h+Code], eax call j___scrt_is_managed_app 倒数第二个call 第四层: 第二个call 第五层: 只有一个call直接进 第六层: jmp mainCRTStartup
1 2 3 4 5 6 7 8 9 10 11 12 13 14 x86 release: 第一层: push eax ; envp push edi ; argv push dword ptr [esi] ; argc call _main 第二层: call ___security_init_cookie jmp __scrt_common_main_seh 直接jmp
选择高亮模式进行调试是个看着会舒服很多:
第三种方式:导入表查看 首先生成如下代码exe
Release x86:
1 2 3 4 5 6 7 8 9 #include <stdio.h> #include <Windows.h> int main () MessageBoxA (NULL ,"Msg" ,"rkvir" , MB_OK); return 0 ; }
静态调试查询演示: 拖入IDA9.0
首先,它已经直接识别出main函数:如下:
如果没有识别出来呢?
我们可以去导入表内看看:如下:用到的api都在下显示了
我们ctrl+F进行一下搜索:如下:
双击点击进入:如下:
我们会看到他进行了一个跨模块的引用:
@16是什么呢?
就是它的参数:32位加4字节一个
MessageBoxA四个参数
前面粉色的代表什么呢?
粉色就代表着它是一个跨模块的调用,它是在其他的模块里拥有的这么一个东西
上方int (__stdcall *MessageBoxA)还说明其返回值,以及调用约定
接下来我们直接对其进行一个右键+交叉引用的形式来找他的这个位置,如下:
发现两个位置都在调用,其实两个位置都一样,如下:
会发现我们已经成功找到main函数了。
动态调试演示: 利用x64dbg打开程序,右键——>搜索——>所有模块——>跨模块调用如下:
在左下角的搜索框内搜索:MessageBoxA:如下:
然后双击直接进入:
利用方法找到指定功能: 上述的这些方法也不见得非得用来找main函数,也可以用来找一些指定的功能。
比方说我来写这样一个程序:(选择MFC程序)
创建新项目:如下
然后直接生成这个文件点击资源文件选择MFCApplication1.rc进入如下界面:
并且修改成上图模样,然后右键button1属性
修改如下:
然后双击Msg:如下:
跳转到此处:如下:
并在其中写入弹窗代码:如下:
完成以后配置一下项目属性:设置成如下:
完成以后我们直接**右键——>重新生成**生成一个exe文件。如下:
其能达到这么一个效果:如下:
分析: 我们该如何找到如下功能点呢?
拖入ida以后:
我们可以看看其字符串,也可以看看其导入表。
这里我直接对导入表进行一个翻看然后ctrl+F搜索MessageBoxA然后找到其函数以后再对其进行右键查询交叉引用找到其调用然后对函数进行一个重命名:如下:
接下来对其再进行一个交叉引用:如下:
跳转过来以后我们继续对其进行交叉引用继续往上追:如下:
上层结果如下:
接下来我们给原本的这个程序加点东西来分析:
然后给其添加变量,如下:
这样设置完两个变量之后我们双击就不弹窗,我们让其做一个对比比较:
功能:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void CMFCApplication1Dlg::OnBnClickedButton1 () UpdateData (TRUE); if (m_IntA == m_IntB) { MessageBoxA (NULL , "Success!" , "Msg" , MB_OK); } else { MessageBoxA (NULL , "Faild!" , "Msg" , MB_OK); } UpdateData (FALSE); }
如下:
然后重新生成 。
先将其拖入ida中加载,有一些慢,那我们进行一下动态调试:如下:
现在我们要做的就是要找出他的对比:
可以看到有如下效果:
先将其运行起来:如下:
那么现在呢我们就是要找出他其中的对比。
我们直接**右键搜索——>跨模块调用**
从这里找到他的弹窗的那个东西! !!
我们找他是有一定依据的:
1 2 3 4 弹窗 MessageBoxA/W afxMessageBox CreateWindow
我们可以追踪到他的根源,我们可以做出如下操作:
1 bp MessageBoxA 下断点(软件断点)
然后回车,这样他就根据我们的api给我们下了一个断点。如下:
又或者我们可以来查看跨模块调用以后直接搜索这个函数MessageBoxA,如下:
然后双击进入,再点击如下:
随便点一个跟进去,无论是不是你都可以下个断点,如下:
不论是上面的那种方式我们都是可以找到这个位置的。
接下来让其运行起来我们就可以进行调试了,然后点击按钮:如下:
接下来我们还要找一个向上的堆栈:他停在上面的断点后,我们点击调用堆栈如下:
调用堆栈就你来源于哪,就是你上一级的调用和上上一级的调用都是来源于哪。
或者你调用堆栈都不用找,直接在堆栈窗口,右键选择转到ESP,如下:
这里就直接找到了:如下:
成功找到了返回地址。
既然已经找到了其返回地址,我们来分析一下这段逻辑:如下:
我们可以看到jne mfcapplication1.6253AA这条指令,来执行的跳转,如果失败他就会是一条虚线跳转到后面指定的地址6253AA,成功则继续执行向下的逻辑。
我们可以看到其上方有个jne的上方有个cmp,不出意外的情况下这个cmp就起到了一个关键的对比作用:于是我F2下个断点来分析:如下:
然后我们直接给其运行起来:如下:
然后我们再给其设置个值然后点击按钮看看,如下:
点击完毕以后其断在了这里:如下:
他断在这里以后我们查看其后面对应存储的值都在哪:观察如下:
edx:
然后我们右键转到内存中指定地址查看其对应所存值:如下:
其[ecx+D8]内存中对应存的值正是0
然后我们点击运行:如下:0并不等于2于是其发生跳转
继续实验:我们重新调整值:如下
观察所存值的变化:如下:
当他们两者相同时,我F8向下走一步我们会发现**ZF位**就等于1了,也就说明其两者相减为0也就是说,其两者相等:如下:
既然两者相等再运行他自然而然的就走向成功了,如下:
扩展: 现在我们大概知道了他的运行逻辑,那么是不是可以尝试逆转一下结果呢,让本该Faild的,变成Success
一个Msg停在此处:如下:
法一 :修改内存地址中的值为2:如下:
一直F8下一步发现成功逆转结果:
法二 :在发生跳转之前改变flag标志位ZF的值:如下:
双击ZF就改了:如下:
成功逆转。
法三 :直接改变跳转指令:
快捷键“Space”直接修改汇编指令:如下:
修改完成后成功逆转,如下:
法四 :直接将jne指令nop掉:
成功逆转,如下:
以上的四种方法也就是,我们破解的一种思路,也是我们功能定位的一种思路。
函数调用约定:(第二天) 示例代码如下:
1 2 3 4 5 6 7 8 9 10 #include <stdio.h> void test () printf ("HelloWorld!\r\n" ); } int main () test (); return 0 ; }
对其生成的exe文件拖入IDA进行调试:进入到如下位置:如下:
一般来说第二个call就是我们自己的函数。
高版本的编译器就是如下:
上下两个call:
第一个是编译器给你加的一个安全检查,获取类似一个线程id之类,反正就是做一个安全检查
第二个同样是一个安全检查Checkesp,检查你的堆栈是否是安全的,是否是平衡的。
我们来利用x64dbg来动态调试来看一看会更明确一些。如下:
上面是走过来的流程我们主要看下面两张图:如下:
第一个call:
第二个call:
其实他的安全检查也是可以删掉的在设置内进行一下调整,如下:
现在我将上述规则设置成默认值,然后重新生成exe来调试看看呢:如下:
我们会发现下面那个checkEsp不见了对吧。
既然如此,那么我们尝试给他的所有保护都给关了,看看程序最原始的状态是个什么样子:如下:
还有将SDL检查关闭:如下:
重新生成。
我们已经将能关的的都尽量关了,现在main函数长这个样子:如下:
进入下面这个call就是我们自己写的那个函数test:如下:
ida打开看看test函数:如下:
现在我们进入test程序来分析这个函数,这段汇编大概干了些什么:右键如下可以进行一下记录:
记录分析的内容如下展示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 test proc near push ebp ; 保存环境,保存原始ebp的值,因为一会会把esp的值覆盖到现有的ebp上 mov ebp, esp ; 把esp给到ebp,然后后续在函数内部均使用ebp作为基准进行寻址 sub esp, 40h ; 保护原有堆栈不被覆盖,抬出一块 push ebx ; 保存ebx,esi,edi的值,函数的使用过程中可能会用到,防止原有的值丢失 push esi push edi mov ecx, offset unk_50F003 call j_@__CheckForDebuggerJustMyCode@4 ; 编译器添加的安全检查函数 push offset Format ; "HelloWorld!\r\n" call j__printf ; 这里就是我们打印用的一个printf函数 add esp, 4 ; 保持堆栈平衡,平掉1个参数(4字节)就是上面的那个安全检查函数 pop edi pop esi pop ebx ; 还原现场ebx,edi,esi的值 mov esp, ebp ; 还原esp的值 pop ebp ; 原有的ebp的值还原给ebp retn ; 返回函数结束 test endp
函数调用约定: 1 2 3 _cdecl _stdcall _fastcall
_cdecl: 示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdio.h> #include <Windows.h> int _cdecl test (int a,int b,int c,int d,int f) return a + b + c + d + f; } int main () int nRes = test (1 , 2 , 3 , 4 , 5 ); printf ("Res = %d \r\n" , nRes); return 0 ; }
生成exe后拖入ida进行一手分析:
首先我们来到main函数下,如下:
我们来着重关注一下这一段:
1 2 3 4 5 6 7 push 5 ; int push 4 ; int push 3 ; int push 2 ; int push 1 ; int call _test add esp, 14h ;平栈上面各是4字节一共20字节也就是0x14个字节
点击_test我们会进入一个跳转表:如下:
跳入我们的函数test:如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 arg_0= dword ptr 8 ;这里也就是arg_0参数他在堆栈中的地址就在:[ebp + 8h] arg_4= dword ptr 0Ch ;[ebp + Ch] arg_8= dword ptr 10h ;[ebp + 10h] arg_C= dword ptr 14h ;[ebp + 14h] arg_10= dword ptr 18h ;[ebp + 18h] 他存储了如下一些内容: [ebp] : ret [ebp + 8h] [ebp + Ch] [ebp + 10h] [ebp + 14h] [ebp + 18h]
然后我们利用x64dbg来进行查看我们调用这个函数时堆栈的相关变化:如下:
当我们跟进call以后,堆栈就会存入等会我们要返回的地址:如下:
push ebp:如下:
进入堆栈的是如下内容:
1 2 3 4 5 6 7 $ ==> 0019FE88 0019FEF4 ebp $+4 0019FE8C 004503D2 返回到 funcrule._main+22 自 funcrule.__enc$textbss$end+2373 $+8 0019FE90 00000001 $+C 0019FE94 00000002 $+10 0019FE98 00000003 $+14 0019FE9C 00000004 $+18 0019FEA0 00000005
mov ebp,esp:如下效果:
sub esp,40:进行抬栈操作:这40h个字节能够保证我们在函数堆栈内出现问题不会淹没到原有的堆栈 ,如下:
这中间就相当于是一层缓冲层:
底下呢就是我们的老的堆栈,上方呢就是我们为我们的内部函数的堆栈,中间呢是缓冲层防止我们内部函数的堆栈溢出淹没到我们原来的堆栈。
后面的指令就是进行加法以后存储到eax中:如下
进栈多少就出栈多少,一一pop出,如下:
mov esp,ebp:指令将ebp赋值给esp就相当于将前面抬栈的部分全部抹掉了 ,所以此处不需要平栈他也能正常的回来。如下:
注意观察此时栈顶esp对应存储的值正是原始ebp值:直接pop即可还原ebp:如下:
ebp也就被还原到上一层栈的栈底
ret指令,栈顶的值pop给eip:我们也就会进行一个跳转:如下:
但是现在我们还没能完全还原堆栈,因为还有如下内容:
于是我们就需要add esp 14h进行平栈操作。
上面就是比较经典的_cdecl函数调用约定的一个过程。
_stdcall: 示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdio.h> #include <Windows.h> int _stdcall test (int a,int b,int c,int d,int f) return a + b + c + d + f; } int main () int nRes = test (1 , 2 , 3 , 4 , 5 ); printf ("Res = %d \r\n" , nRes); return 0 ; }
生成exe然后拖入ida分析,如下:
我们通过观察会发现它和_cdecl有一个显著的区别,他调用完毕之后没有进行平栈操作:
1 2 3 4 5 6 push 5 ; int push 4 ; int push 3 ; int push 2 ; int push 1 ; int call _test
接下来我们进入test函数内部进行一个分析看看:如下:
我们会发现其与_cdecl只有一个显著的不同,就是在最后是retn 14h
retn 14h是什么意思呢?
相当于在返回之前平掉堆栈里面的14h个字节,这就是其与_cdecl的不同之处,_stdcall是内平栈,_cdecl是外平栈。
_fastcall: x86 debug
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 #include <stdio.h> #include <Windows.h> int _fastcall test (int a,int b,int c,int d,int f) return a + b + c + d + f; } int main () int nRes = test (1 , 2 , 3 , 4 , 5 ); printf ("Res = %d \r\n" , nRes); return 0 ; }
利用x64dbg进行一手分析:运行到如下位置:
我们会发现他的参数不全是push,他是如下的结构:存入的参数
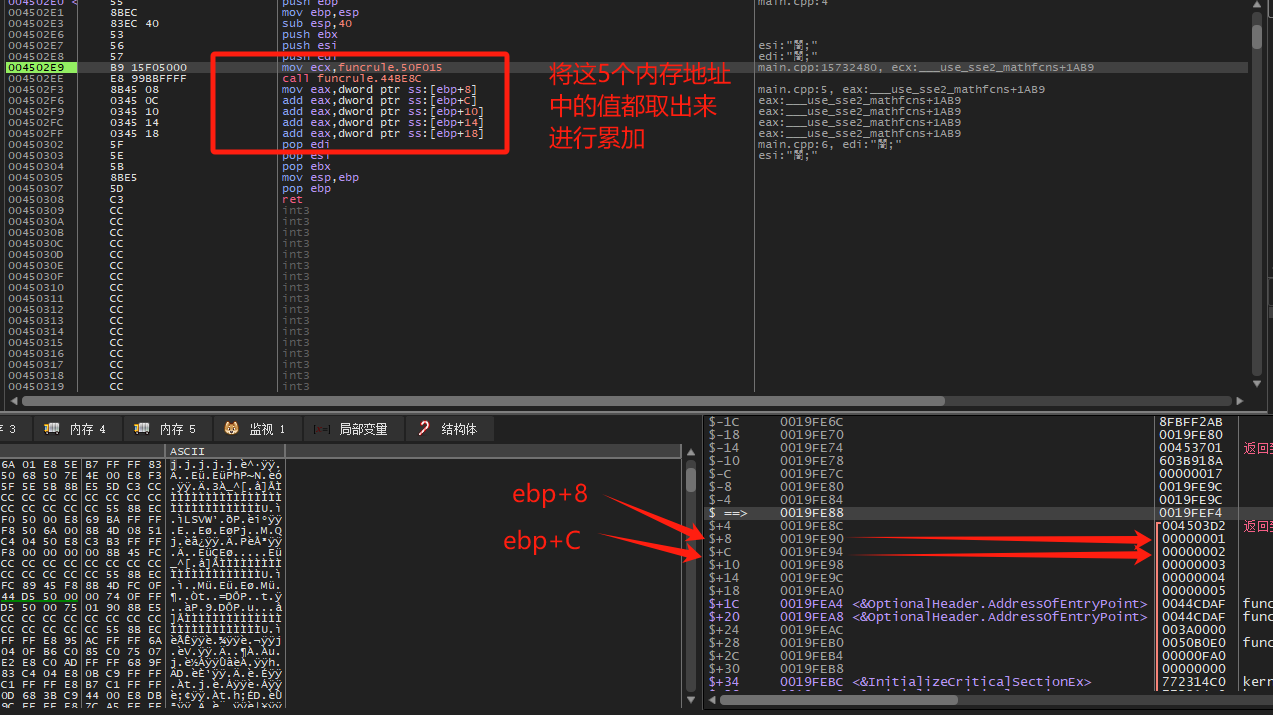
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 ;_fastcall:test函数内容 push ebp mov ebp,esp sub esp,48 push ebx push esi push edi ;我们会发现他把两个参数放入了局部变量里面。 mov dword ptr ss:[ebp-8],edx mov dword ptr ss:[ebp-4],ecx mov ecx,funcrule.50F015 call funcrule.44BE8C mov eax,dword ptr ss:[ebp-4] add eax,dword ptr ss:[ebp-8] ;+号是参数,-号是局部变量 add eax,dword ptr ss:[ebp+8] add eax,dword ptr ss:[ebp+C] add eax,dword ptr ss:[ebp+10] pop edi pop esi pop ebx mov esp,ebp pop ebp ret C
这里自己调试调试看参数存放的位置就看明白了,或者可以自己画画堆栈图,就理解了。
复杂结构分析: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <stdio.h> #include <Windows.h> typedef struct _Res { int a; int b; }Res; Res test (int a, int b, int c, int d, int f) { Res obj; obj.a = a + b + c; obj.b = d + f; return obj; } int main () Res nRes = test (1 , 2 , 3 , 4 , 5 ); printf ("Res = %d-%d \r\n" , nRes.a, nRes.b); return 0 ; }
这里堆栈结构不过多说,自己进行x64dbg的时候可以看看对应内存地址,以及堆栈的变化来分析。
可以写入更多变量来分析。
if-else语句识别分析:(第三天) 01.if 示例代码1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <stdio.h> #include <stdlib.h> int main () int nFlag = 0 ; scanf ("%d" , &nFlag); if (nFlag == 10 ) { printf ("Flag = %d" , nFlag); } system ("pause" ); return 0 ; }
然后顺利生成如下四个版本的exe:x64 debug,x86 debug,x64 release,x86 release
不过在有些环境下他运行报错了,如下:
我们对其进行一下如下设置,即可成功:
分析:x86 debug版本如下 首先将其拖入ida找到其主函数,进入主函数main:如下:
简单分析一下我们自己的功能函数代码:如下:
具体分析入戏:都在代码注释上:如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 .text:00461922 mov [ebp+Var1], 0 ; Var1 = 0,这一部分开始就是我们自己代码 .text:00461929 lea eax, [ebp+Var1] ; eax = &Var1 .text:0046192C push eax ; 压栈,可以理解为压入&Var1 .text:0046192D push offset Format ; 字符串:"%d" .text:00461932 call j__scanf .text:00461937 add esp, 8 ; 平栈2参数 .text:0046193A cmp [ebp+Var1], 0Ah ; 判断Var1与0Ah是否相等 .text:0046193E jnz short loc_461951 ; 如果不等就跳转推出,如果相等向下走 .text:00461940 mov eax, [ebp+Var1] ; 将Var1的值给eax .text:00461943 push eax ; 然后将eax进行压栈,push Var1 .text:00461944 push offset aFlagD ; "Flag = %d" .text:00461949 call j__printf .text:0046194E add esp, 8 ; 平栈两个参数 .text:00461951 .text:00461951 loc_461951: ; CODE XREF: _main+4E↑j .text:00461951 push offset Command ; "pause" .text:00461956 call j__system ; 调用system
分析:x64 debug版本如下 首先将其拖入ida找到其主函数,进入主函数main:如下:
自己可以分析一下不过多展示:如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 .text:000000014007992B mov [rbp+0F0h+Var1], 0 .text:0000000140079932 lea rdx, [rbp+0F0h+Var1] .text:0000000140079936 lea rcx, Format ; "%d" .text:000000014007993D call j_scanf .text:0000000140079942 cmp [rbp+0F0h+Var1], 0Ah .text:0000000140079946 jnz short loc_140079957 .text:0000000140079948 mov edx, [rbp+0F0h+Var1] .text:000000014007994B lea rcx, aFlagD ; "Flag = %d\r\n" .text:0000000140079952 call j_printf .text:0000000140079957 .text:0000000140079957 loc_140079957: ; CODE XREF: main+56↑j .text:0000000140079957 lea rcx, Command ; "pause" .text:000000014007995E call j_system
02.if-else 示例代码2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <stdio.h> #include <stdlib.h> int main () int nFlag = 0 ; scanf ("%d" , &nFlag); if (nFlag == 10 ) { printf ("Flag = %d\r\n" , nFlag); } else { printf ("Flag != 10" ); } system ("pause" ); return 0 ; }
然后依旧是生成如下四个版本的exe:x64 debug,x86 debug,x64 release,x86 release
分析:x86 debug版本如下 首先将其拖入ida找到其主函数,进入主函数main:如下:
我们会发现有一段汇编很特殊:如下:
1 2 3 4 .text:004618FC lea edi, [ebp+var_D0] .text:00461902 mov ecx, 34h .text:00461907 mov eax, 0CCCCCCCCh .text:0046190C rep stosd
我们来动态调试来分析一下:如下:
其就会将抬栈的部分全部刷新为0cccccccch。
下面我们来观察看,我们的main函数主体内容的汇编,也就是我们的if-else语句:如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 mov dword ptr ss:[ebp-C],0 | [VarC]=0 lea eax,dword ptr ss:[ebp-C] | eax = &Varc push eax | push eax push <if_else."%d"...> | BB9E50:"%d" call if_else.AFA99C | scanf函数 add esp,8 | 平栈平两个参数 cmp dword ptr ss:[ebp-C],A | 判断Varc和10 jne if_else.B01953 | 判断与10是否相等不相等则跳转 mov eax,dword ptr ss:[ebp-C] | eax = Varc push eax | push Varc push <if_else."Flag = %d\r\n" | BB9E54:"Flag = %d\r\n" call if_else.AFA4C4 | printf add esp,8 | 平栈两个参数 jmp if_else.B01960 | 因为这里是if-else结构他在执行完if后会有一个无条件jmp push <if_else."Flag != 10"... | main.cpp:14, BB9E64:"Flag != 10" call if_else.AFA4C4 | add esp,4 | push <if_else."pause"...> | system函数入栈参数,BB9E74:"pause"
03.if-elseif-else 示例代码3:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <stdio.h> #include <stdlib.h> int main () int nFlag = 0 ; scanf ("%d" , &nFlag); if (nFlag == 10 ) { printf ("Flag = %d\r\n" , nFlag); } else if (nFlag == 20 ) { printf ("Flag = %d\r\n" , nFlag); } else { printf ("Flag != 10" ); } system ("pause" ); return 0 ; }
然后依旧是生成如下四个版本的exe:x64 debug,x86 debug,x64 release,x86 release
分析:x86 debug版本如下 x64dbg分析其实和上面的大差不差关键点是要明白他的jxx的跳转逻辑注意观察:如下:
04.多条件判断 示例代码4:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <stdio.h> #include <stdlib.h> int main () int nFlagA = 0 ; int nFlagB = 0 ; scanf ("%d" , &nFlagA); scanf ("%d" , &nFlagB); if (nFlagA == 10 && nFlagB == 11 ) { printf ("Flag = %d %d\r\n" , nFlagA,nFlagB); } else if (nFlagA == 20 || nFlagB == 10 ) { printf ("Flag = %d %d\r\n" , nFlagA, nFlagB); } else { printf ("Flag != 10" ); } system ("pause" ); return 0 ; }
然后依旧是生成如下四个版本的exe:x64 debug,x86 debug,x64 release,x86 release
分析:x86 debug版本如下 x64dbg分析:
switch语句识别分析:(第四天) 01.switch-3case 无源码版本分析:x86 debug:
分析:
main函数内容如下:
后面我们会发现其有三个分支,满足条件就会跳转至不同的地址:如下:
其大致代码逻辑,直翻应该是如下这种的是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 VarC = 0 ; scanf ("%d" , &VarC);if (VarC === 1 ){ printf ("nFlag == 1\n" ); goto _ret; } if (VarC === 2 ){ printf ("nFlag == 2\n" ); goto _ret; } if (VarC === 3 ){ printf ("nFlag == 3\n" ); goto _ret; } _ret: system ("pause" );return 0
但是我们稍加思考我们就会发现它其实就是一个switch结构:如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 VarC = 0 ; scanf ("%d" , &VarC);switch (VarC){ case 1 : { printf ("nFlag == 1\n" ); break ; } case 2 : { printf ("nFlag == 2\n" ); break ; } case 3 : { printf ("nFlag == 3\n" ); break ; } } system ("pause" );return 0 ;
02.switch-6case 其与3case最大的区别就是有无跳转表
无源码版本分析:x86 debug:
首先进行一个初步观察如下图:
并且通过阅读汇编代码我们会发现,它有如下操作:(平索引)
何为平索引,为什么要这么做呢?
首先我们要了解一个概念,跳转表:
跳转表是一个数组:
比方说我们来一个case 10这时候他要去数组里找到对应的需要跳转到的分支的地址。
因为在这个跳转表的每一个索引下都存的是一个分支的地址。
理论上来说我们应该跳转到索引为10下存储的地址,但是我们知道的是数组的索引都是从0开始的。所以一开始的时候我们需要进行一个 sub ecx,1进行一个平索引的操作。
其中sub ecx,1中的1不见的就是1 :
它是第一个case的值距离0有多远,然后强行把索引平到从0开始。
首先我们拿起和最大的索引进行一个cmp比较,ja的指令意思就是如果它大于5则跳转,跳出switch无法处理,如下图:
然后我们继续观察会发现这个,这个就是跳转表的关键内容:如下:
1 jmp ds:jpt_461961[edx*4] ; switch jump
jpt_461961:这个是跳转表数组的首地址
edx:索引
4:size=4
这个时候我们直接键盘输入g:如下:
然后在其中输入数组的首地址也就是:jpt_461961进行一个跳转:如下:
这里展示的就是一个实实在在的跳转表:
1 2 3 4 5 6 .text:00461A1C jpt_461961 dd offset loc_461968 ; DATA XREF: _main_0+71↑r .text:00461A20 dd offset loc_461977 ; jump table for switch statement .text:00461A24 dd offset loc_461986 .text:00461A28 dd offset loc_461995 .text:00461A2C dd offset loc_4619A4 .text:00461A30 dd offset loc_4619B3
每一个都是dd也就是4字节。
其中:
1 jmp ds:jpt_461961[edx*4] ; switch jump
它的意思就相当于是首地址(00461A1C) + edx*4。
loc_461986就是真实分支所在位置。
比方说3*4:
也就是首地址+C = 00461A28:我们取出这个索引下对应的跳转地址:00461995我们按下g跳转到这个地址,如下:
接下来我们来看看在动态调试时,这个跳转表长什么样子呢?
其就是首地址+索引*4我们ctrl+G进行一下跳转到地址表位置:
不过要注意一点你要先行运行到此处才会有跳转表:如下:
输入3:
在这里他会有跳转表位置:如下:
将这个地址拿出来也就是首地址:如下:
我们在内存窗口直接ctrl+g输入这个地址转到,内存中的位置,这就是我们的跳转表的数组存储位置如下 :如下:
其中存的就是汇编中对应索引需要跳转到的地址,是小端序。
03.switch-6case缺项 无源码版本分析:x86 debug:
首先进行一个初步观察如下图:
我们会发现它识别出来了8个case:
他会给我们进行一个补齐,直接跳转到最后,相当于跳出switch:如下:
04.switch-6case单项不连续 无源码版本分析:x86 debug:
首先进行一个初步观察,我们直接观察对应得比较部分,如下:
第一个判断其是不是大于888,如果大于直接跳出无法处理,也就是结束掉。
第二个判断其是不是就是888,如果等于则直接跳转到888对应的分支上去。
如果都不是那就继续往下走,也就是走正常的跳转表。也就五个分支。
05.switch-6case多线表 这个多线表里面有很多的不连续,它的跳转呢就有如下几种情况:如下:
继续往下走就是小于100的。
如若我们进入大于100的分支中,他还会有一个跳转表,如下:
我们可以进入这个跳转表内看看内容,如下:
如若我们进入等于100的分支中,则如下:
然后运行完毕,直接跳出switch。
如若我们进入小于100的分支中,我们可以观察其跳转表,如下:
由上面的例子我们可以看出,一个程序中未必只会有一个跳转表,它可以做一个分割,上面就做了如下分割:
06.switch-6case无线表无break 这种情况下其没有跳转表,都是各跳个的基本,如下:
我们会发现其基本不连续,如果要形成跳转表其会形成大量的空项,会对资源造成极大的浪费。
01.while循环 源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <stdio.h> #include <stdlib.h> int main () int nFlag = 0 ; while (nFlag <= 100 ) { printf ("nFlag = %d\n" , nFlag); nFlag++; } system ("pause" ); return 0 ; }
分析x86 debug:main函数主要内容如下:
我们直接对其汇编代码进行直译:如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Var8 = 0 ; _CmpCode: if (Var8 > 100 ){ goto _EndCode; } else { printf ("nFlag = %d" , Var8); Var8++; goto _CmpCode; } _EndCode: system ("pause" );return 0 ;
经过整理可以整理成如下的模样:
1 2 3 4 5 6 for (int Var8=0 ; Var8 <= 100 ; Var8++){ printf ("nFlag = %d" , Var8); } system ("pause" );return 0 ;
或
1 2 3 4 5 6 7 8 Var8 = 0 ; while (Var8 <= 100 ){ printf ("nFlag = %d" , Var8); Var8++; } system ("pause" );return 0 ;
02.for循环 源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 #include <stdio.h> #include <stdlib.h> int main () for (size_t i = 0 ; i < 100 ; i++) { printf ("nFlag = %d\n" , i); } system ("pause" ); return 0 ; }
我们直接分析x86 debug:main函数如下:
我们尝试直译,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 nIndex = 0 ; goto _CmpCode:_IncCode: nIndex++; _CmpCode: if (nIndex > 100 ){ goto _EndCode; } else { printf ("nFlag = %d\n" ,nIndex); goto _IncCode; } _EndCode: system ("pause" );return 0 ;
03.dowhile循环 源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <stdio.h> #include <stdlib.h> int main () int nFlag = 0 ; do { printf ("nFlag = %d\n" , nFlag); nFlag++; } while (nFlag < 100 ); system ("pause" ); return 0 ; }
我们分析x86 debug:main函数内容如下:
直译如下:
1 2 3 4 5 6 7 8 9 10 nIndex = 0 ; _CmpCode: printf ("nFlag = %d \n" ,nIndex);nIndex++; if (nIndex <= 100 ){ goto _CmpCode; } system ("pause" );return 0 ;
优化成do-while的形式,如下:
1 2 3 4 5 6 7 8 9 nIndex = 0 ; do { printf ("nFlag = %d \n" ,nIndex); nIndex++; } while (nIndex <= 100 )system ("pause" );return 0 ;
04.循环嵌套 源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdio.h> #include <stdlib.h> int main () for (size_t i = 0 ; i < 100 ; i++) { for (size_t n = 0 ; n < 200 ; n++) { printf ("i = %d:n = %d\n" , i, n); } } system ("pause" ); return 0 ; }
直接分析x86 debug:main如下:
直译汇编如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 nIndexA = 0 ; goto CmpCodeA;IncCodeA: nIndexA++; CmpCodeA: if (nIndexA > 100 ){ goto EndCode; } else { nIndexB = 0 ; goto CmpCodeB; IncCodeB: nIndexB++; CmpCodeB: if (nIndexB > 200 ) { goto JmpACode; } else { printf ("i = %d:n = %d\n" ,nIndexA,nIndexB); goto IncCodeB; } } JmpACode: goto IncCodeA; EndCode: system ("pause" );return 0 ;
数组与指针识别分析:(第六天) 01.函数内的数组 数组与多个同类型变量的区别: 源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> #include <stdlib.h> int main () int arr[] = { 1 ,2 ,3 ,4 ,5 }; printf ("%d,%d,%d,%d,%d\n" , arr[0 ], arr[1 ], arr[2 ], arr[3 ], arr[4 ]); int a = 1 ; int b = 2 ; int c = 3 ; int d = 4 ; int e = 5 ; printf ("%d,%d,%d,%d,%d\n" , a, b, c, d, e); system ("pause" ); return 0 ; }
x86 debug分析如下:
将这段连续的地址转换成数组:如下
然后点击OK即可。
然后我们回到汇编中它就会变成如下的样子:
1 2 3 4 5 mov [ebp+var_18], 1 mov [ebp+var_18+4], 2 mov [ebp+var_18+8], 3 mov [ebp+var_18+0Ch], 4 mov [ebp+var_18+10h], 5
var_18:数组首地址。
数组寻址:
数组首地址+offset(sizeof(type)) * index
如下:
1 int arr[] = { 1 ,2 ,3 ,4 ,5 };
数组下标就为:0,1,2,3,4
然后利用数组下标也就是他的索引 * type size:offset(sizeof(type)) * index
至于后续的什么shl,imul都是为了算出他的对应地址,不用过多纠结。
我们只需要关注到,数组其在内存中是连续的即可。
我们继续观察后面的同类型int变量: 如下:
其与数组最大的区别就是他在内存中的位置并不是连续的,如下:
动态调试如下:
所以其在传参的时候也比较单纯,不用像上面一样需要计算相对地址什么的,直接就可以传其地址即可,如下:
这就是他们上面的一些差异。
字符数组: 演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> #include <stdlib.h> int main () char szStr[] = { 'r' ,'k' ,'v' ,'i' ,'r' ,'\0' }; char szStr2[] = "rkvir" ; system ("pause" ); return 0 ; }
上面两种字符串,在内存中存储位置是不一样的,我们可以拖入ida观察一下:如下:
后者存储在数据段:如下:
按一下a就可以快捷自动识别出来了,如下:
02.数组作为参数 演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdio.h> #include <stdlib.h> void showArr (char buffer[]) printf ("%s" , buffer); } int main () char szStr[] = { 'r' ,'k' ,'v' ,'i' ,'r' ,'\0' }; showArr (szStr); system ("pause" ); return 0 ; }
x86 debug:分析动态调试找到main函数位置:如下:
[ebp-10]这个位置正是数组头也就是首地址:如下
将这个字符串的首地址存入了eax中:如下:
它后面紧接着调用来一个函数,这个函数正是我们自定义的函数showArr:
通过观察我们发现它传参不是说像其他传参一样压入一个值,它直接是压入了字符串数组的首地址进入函数中 。
x64 debug:分析动态调试找到main函数位置:如下:
因为64位的程序函数调用约定执行的是_fastcall的所以它传如函数的方式是前四个参数都是放入寄存器中的。所以它在传参的时候是将首地址存入了寄存器中,如上图所示。
03.数组作为返回值 演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <stdio.h> #include <stdlib.h> #include <string.h> char * showArr (char buffer[]) memcpy (buffer, "HelloWorld" , 11 ); return buffer; } int main () char buffer[20 ]; printf ("%s" , showArr (buffer)); system ("pause" ); return 0 ; }
和02的情况差不太多。
main函数下目标函数位置如下:
下面第一个函数是printf函数。
总结就是,数组在函数之间传递直接传递的都是一个地址,也就是自己的首地址。可以自己动态调试去分析,不断的观察内存和堆栈之中的变化情况。
04.下标和指针寻址 演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <stdio.h> #include <stdlib.h> int main () char * p = NULL ; char buffer[] = "H ello" ; p = buffer; printf ("%c" , *p); printf ("%c" , buffer[0 ]); system ("pause" ); return 0 ; }
动态调试,我们自己的位置位于:如下:
指针寻址: 这里我们直接将hell存入堆栈中的ebp-1C中,如下:
然后将其存入eax中,并将o存入cx中:如下:
他将其地址存入栈内:如下:
最后大概造成如下效果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 char buffer[] = "H ello"; 对应的就是: mov eax,dword ptr ds:[A97E50] | eax:"Hello", 00A97E50:"Hello" mov dword ptr ss:[ebp-1C],eax | mov cx,word ptr ds:[A97E54] | mov word ptr ss:[ebp-18],cx | p = buffer; 对应的就是: mov dword ptr ss:[ebp-C],eax | [ebp-0C]:"Hello" *p 对应的就是: mov eax,dword ptr ss:[ebp-C] | [ebp-0C]:"Hello" movsx ecx,byte ptr ds:[eax] | eax:"Hello" ;这一段就会取出这段地址为起点,宽度为8bit的数据,也就是一字节也就是H
上述就是指针寻址。
下标寻址: 主要代码位于如下:
注意此处:首地址是ebp-1C,ecx代表的是索引*typesize
05.多维数组 演示代码1如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <stdio.h> #include <stdlib.h> int main () int a[4 ] = { 1 ,2 ,3 ,4 }; int b[2 ][2 ] = { {1 ,2 },{3 ,4 } }; printf ("%d" , b[0 ][1 ]); system ("pause" ); return 0 ; }
这个时候我们就要看一下了他们在内存中有什么区别。
x86 debug分析如下:
我们可以看看他们在内存中的位置:如下:
一维数组:
二维数组:
通过实际观察可知,就存储而言一维数组和二维数组是没有变化的,他们在内存中都是连续存储的。本质上二者并无差别。
二维数组的寻址方式: a[i]:
寻址公式 = 首地址 + i*typesize
a[i][j]:
寻址公式 = (首地址 + j*typesize) + i*(typesize*j)
对于二维数组的寻址公式可以这么理解,先找到第 j 列的地址以后,再根据确定下来的新首地址找第 i 行地址。
第 j 列:新首地址 = 首地址 + j*typesize
此时新数组的大小也变了变成了 新typesize = j * typesize
第 i 行:地址 = 新首地址 + i * 新typesize
也就是:寻址公式 = (首地址 + j*typesize) + i*(typesize*j)
补充:
二维数组的内存布局通常是按行优先(Row-major order)存储的,即将每一行的元素顺序地存储在内存中。数组在内存中的布局如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 arr[0] [0] arr[0] [1] arr[0] [2] arr[0] [3] | | | | ↓ ↓ ↓ ↓ 0 x1000 0 x1004 0 x1008 0 x100Carr[1] [0] arr[1] [1] arr[1] [2] arr[1] [3] | | | | ↓ ↓ ↓ ↓ 0 x1010 0 x1014 0 x1018 0 x101Carr[2] [0] arr[2] [1] arr[2] [2] arr[2] [3] | | | | ↓ ↓ ↓ ↓ 0 x1020 0 x1024 0 x1028 0 x102C
行优先存储(Row-major order) 二维数组在内存中是按行优先顺序存储的。在访问二维数组元素时,计算地址的方式与一维数组类似,但需要考虑行和列的索引。假设有一个 m x n 的二维数组:
对于元素 arr[i][j],它的内存地址可以通过以下公式计算:
地址 = 基址 + (i * n + j) * 元素大小
其中:
i 是行的索引j 是列的索引n 是每行的元素数量元素大小 是数组中每个元素的字节数
通过观察我们的程序:如下:
我们会发现它进行了两次运算和我们上面所说一致。
06.指针数组 演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> #include <stdlib.h> int main () const char * buffer1 = "h1111" ; const char * buffer2 = "h2222" ; const char * buffer3 = "h3333" ; const char * buffer4 = "h4444" ; const char * arr[] = { buffer1,buffer2 ,buffer3 ,buffer4 }; for (size_t i = 0 ; i < 4 ; i++) { printf ("%s" , arr[i]); } system ("pause" ); return 0 ; }
x86 debug 调试分析一手:如下
07.数组指针 代码演示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> #include <stdlib.h> int main () int a[3 ][3 ] = { {1 ,2 ,3 },{4 ,5 ,6 },{7 ,8 ,9 } }; int (*p)[3 ] = a; for (size_t i = 0 ; i < 3 ; i++) { for (size_t x = 0 ; x < 3 ; x++) { printf ("%d\n" , p[i][x]); } } system ("pause" ); return 0 ; }
我们主要观察这一段:如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 mov dword ptr ss:[ebp-2C],1 mov dword ptr ss:[ebp-28],2 mov dword ptr ss:[ebp-24],3 mov dword ptr ss:[ebp-20],4 mov dword ptr ss:[ebp-1C],5 mov dword ptr ss:[ebp-18],6 mov dword ptr ss:[ebp-14],7 mov dword ptr ss:[ebp-10],8 mov dword ptr ss:[ebp-C],9 ;这一段的作用正好对应代码中的: ;int a[3][3] = { {1,2,3},{4,5,6},{7,8,9} }; lea eax,dword ptr ss:[ebp-2C] mov dword ptr ss:[ebp-38],eax | ;这一段的作用正好对应代码中的: ;int(*p)[3] = a; ;其中这个[ebp - 38]正是对应我们的指针
接下来我们来进一步分析一下内层代码:如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 imul eax,dword ptr ss:[ebp-44],C ;将C*[ebp-44]的值存储进寄存器eax中:其中C是单个元素(一维数组)的数据宽度。 ;[ebp-44]代表的是索引 ;这里就是利用我们的外层索引来判断我们当前处于哪一个一维数组 add eax,dword ptr ss:[ebp-38] ;这里的[ebp-38]存储的正是我们的首地址 ;加上以后就成功确定我们的数组在哪了 ;这时候新的首地址也就是我们当前所处一维数组的首地址!(也就是eax) mov ecx,dword ptr ss:[ebp-50] ;[ebp-50]是我们的内层的索引,赋值给ecx了 mov edx,dword ptr ds:[eax+ecx*4] ;因为我们已经确定了具体是哪个数组,并且上面已经将其首地址取出了,想要取出其中某个具体的值只需要利用公式即可 ;符合二维数组的寻址公式: 新首地址 + 索引*(内层数据的数据宽度) ;地址 = 新首地址(eax) + 内层索引(ecx) * 4(typesize(int)) = eax+ecx*4 push edx push arr.417E50 ;压入格式化字符串 call printf ;调用printf函数 add esp,8 ; 平栈
解释一下为什么要乘以C:
int a[3][3] = { {1,2,3},{4,5,6},{7,8,9} }
这是我们自己的代码,这个二维数组其可以看作是一个一维数组里面存储了一个一维数组,而存储的这个一维数组是由三个int型变量组成。
所以这单个{1,2,3}也就是,3 * typesize(int) = C所以也就可以理解成,这个一维数组,这个数据宽度是C ,也就是新的typesize ,这里我上面写多维数组笔记的时候有记录到。
08.函数指针 演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> #include <stdlib.h> void show (const char * szStr) printf ("%s\n" , szStr); } typedef void (*MyShow) (const char * szStr) int main () MyShow func = show; func ("rkvir" ); system ("pause" ); return 0 ; }
我们看看主函数main分析一手:如下:
我们跟进去发现其就是一个函数跳转表:如下:
跟进去就会发现这其实就是我们的show函数:如下:
后续我们会发现其会call了这个[ebp - 8],也就会自动跳转到我们的这个show函数。上面正是我们的函数指针的一个调用过程:
将函数的地址放到一个变量里,然后我们去call这个变量。
类与对象的识别分析:(第七天) 01.对象布局 未继承对象布局 演示源码:obj.cpp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <stdio.h> #include <stdlib.h> class rkvir { public : rkvir (); ~rkvir (); int geta () int getb () private : int a; int b; struct MyStruct { int c; int d; }; MyStruct m; short e; int f; }; rkvir::rkvir () { b = 200 ; a = 100 ; m.c = 200 ; m.d = 300 ; e = 50 ; f = 500 ; } rkvir::~rkvir () { } int rkvir::geta () return a; } int rkvir::getb () return b; } int main () rkvir rk; system ("pause" ); return 0 ; }
静态调试分析:
我们自己的主要代码就在这一部分:如下
其中这个var_20就是我们的object对象地址:我们的main函数中主要就只有实例化了一个对象:
C++中我们实例化一个对象,就会马上执行其中的构造函数,将对象的各个属性进行一个初始化。
并且我们能够发现其在调用函数之前会进行一个地址传递的操作,这也是一种调用约定_thiscall。
根据上图也可知,构造函数的地址正是sub_450743:进入这个函数可以看到其主要代码,如下:
通过我们自己的C++代码对照,也可知这段代码进行了一个赋值操作:
这里的var_8在构造函数内部起到一个this的作用,相当于是一个指向我们对象的指针。
然后返回我们会发现,他还调用了一个函数sub_45114D,这个函数正是C++特有的析构函数,用于在函数结束以后销毁对象的。
动态调试分析:
找到我们自己的主函数位置:如下:
找到构造函数调用特征了lea,直接进入构造函数内:如下:
可以看到eax存储的就是我们生成对象的首地址,他其实就是内部函数的一个this指针,指向我们的对象首地址,(但他本身并不是对象,只是指向我们已经实例化的对象首地址)对照着右下角的堆栈进行观察,如下:
可以自己在看这段笔记的时候再对照着调试一番。
继承后对象布局 演示源码:virtual.cpp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 #include <stdio.h> #include <stdlib.h> class rkvir { public : rkvir (); ~rkvir (); int geta () int getb () virtual void show () private : int a; int b; struct MyStruct { int c; int d; }; MyStruct m; short e; int f; }; rkvir::rkvir () { b = 200 ; a = 100 ; m.c = 200 ; m.d = 300 ; e = 50 ; f = 500 ; } rkvir::~rkvir () { } int rkvir::geta () return a; } int rkvir::getb () return b; } class xxx :public rkvir{ public : xxx (); ~xxx (); void show () private :}; xxx::xxx () { } xxx::~xxx () { } void xxx::show () printf ("rkvir" ); } int main () rkvir rk; xxx mx; system ("pause" ); return 0 ; }
可以看到xxx继承了rkvir
我们看看静态的汇编代码,如下:
我们可以跟进第一个构造函数内部看看,如下:
第二个构造函数内部,如下:
黄色标注部分就是他的虚函数表的地址:
解释: 虚函数表(vtable,Virtual Table)是面向对象编程中用于支持动态绑定 (也称为多态 )的一种机制。它主要与C++等支持多态的语言相关。为了让程序能够在运行时根据对象的实际类型调用正确的虚函数,虚函数表在后台起着关键作用。
虚函数表的工作原理:
虚函数的声明: 在类中,如果某个成员函数被声明为virtual,编译器就会为该类生成一个虚函数表。虚函数表是一个指针数组,数组中的每个元素指向类中的一个虚函数。继承和覆盖: 当一个类继承另一个类并重写了某个虚函数时,子类会用自己的函数覆盖父类的虚函数。在虚函数表中,指向父类虚函数的指针会被替换成指向子类虚函数的指针。对象和虚函数表的关联: 每个对象(或其子类对象)都会持有一个指向虚函数表的指针。这个指针通常作为对象的一部分存储在内存中,当调用虚函数时,程序会通过该指针找到相应的虚函数表,进而调用正确的函数。多态的实现: 通过虚函数表的机制,C++支持动态多态 。即使你只有基类的指针或引用,在实际调用虚函数时,程序会根据对象的实际类型(不是声明类型)来决定调用哪个版本的虚函数。
接下来我们动态调试 来看看:这个续函数表
上面存储的只是一个指向虚函数表的指针。
我们可以在内存中看到其真实虚函数表地址:如下:
跳转到虚函数表:如下:
跳转进来正是继承的函数:如下:
02.this指针 演示源代码:this.cpp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 #include <stdio.h> #include <stdlib.h> class rkvir { public : rkvir (); ~rkvir (); int geta () int getb () void seta (int a) virtual void show () private : int a; int b; struct MyStruct { int c; int d; }; MyStruct m; short e; int f; }; rkvir::rkvir () { b = 200 ; a = 100 ; m.c = 200 ; m.d = 300 ; e = 50 ; f = 500 ; } rkvir::~rkvir () { } int rkvir::geta () return a; } int rkvir::getb () return b; } void rkvir::seta (int a) this ->a = a; } class xxx :public rkvir{ public : xxx (); ~xxx (); void show () private :}; xxx::xxx () { } xxx::~xxx () { } void xxx::show () printf ("rkvir" ); } int main () rkvir rk; rk.seta (4 ); system ("pause" ); return 0 ; }
我们来拉入ida观察分析一番,如下:
我们直接进入第二个call sub_4524EE,如下:
它就是进行了一个简单的对象内部属性的赋值操作。
动态调试分析:
首先我们进入其main函数位置,并在其内存窗口转到对象空间,如下:
随后进入这个后续的函数中来:如下:
我们代码位于:如下位置:
可以看到它首先将对象空间首地址赋值给了eax,然后再将传入的参数4赋值给了ecx,最后将值4赋给了对象中对应的属性。
达到了一个修改的作用如下:
03.使用对象作为函数参数及返回值 演示代码如下:project13.cpp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 #include <stdio.h> #include <stdlib.h> class rkvir { public : rkvir (); ~rkvir (); int geta () int getb () void seta (int a) virtual void show () private : int a; int b; struct MyStruct { int c; int d; }; MyStruct m; short e; int f; }; rkvir::rkvir () { b = 200 ; a = 100 ; m.c = 200 ; m.d = 300 ; e = 50 ; f = 500 ; } rkvir::~rkvir () { } int rkvir::geta () return a; } int rkvir::getb () return b; } void rkvir::seta (int a) this ->a = a; } class xxx :public rkvir{ public : xxx (); ~xxx (); void show () private :}; xxx::xxx () { } xxx::~xxx () { } void xxx::show () printf ("rkvir" ); } rkvir rkprint (rkvir xx) printf ("%d" , xx.getb ()); xx.seta (500 ); return xx; } int main () rkvir rk; rkvir rk2; rk2 = rkprint (rk); printf ("%d" , rk2. geta ()); system ("pause" ); return 0 ; }
首先找到main函数:如下:
主要是看这个点会比较特殊:如下:
1 2 3 lea eax, [ebp+objrk] ; rk对象地址给到eax,然后压栈,作为参数传入拷贝构造函数 push eax call sub_4524F3 ; 拷贝构造函数
它调用的sub_4524F3函数在我们的代码中并未出现:他其实是一个拷贝构造函数 ,他会将我们即将传入的对象objrk进行一个拷贝,拷贝以后将拷贝后的对象传入,下一个函数当中也就是rk2 = rkprint(rk);
我们来看看这个函数内部:如下:
后面我们直接跟进后续的函数rkprint中:如下
里面有一个调用getb的函数我们可以跟进去看看它的逻辑:如下:
然后我们继续在rkprint函数下向下分析:如下:
传入这个赋值对象,压入要修改的内容1F4h,也就是500
对值进行修改:修改为500对应xx.seta(500);
回到main函数:它继续调用了一个函数,也就是geta函数:如下:
进入函数内部看看内容:如下:
只起到一个作用取出a属性的值,对应代码:printf("%d", rk2.geta());中的rk2.geta()
构造函数与析构函数识别分析:(第八天) 构造函数: 01.局部对象 实验源代码如下:debug.cpp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <stdio.h> #include <stdlib.h> class rk { public : rk (); ~rk (); private : int age; }; rk::rk () { age = 20 ; } rk::~rk () { } int main () rk mk; system ("pause" ); return 0 ; }
ida反编译汇编代码如下:main函数:
构造函数内部对应代码内容如下:age = 20;
02.堆对象 演示代码debug.cpp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <stdio.h> #include <stdlib.h> class rk { public : rk (); ~rk (); private : int age; }; rk::rk () { age = 20 ; } rk::~rk () { } int main () rk *p = new rk (); system ("pause" ); return 0 ; }
拖入ida进入main函数位置,如下:
注释如下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 push 4 ; Size,这里实际上就是需要new的尺寸 call j_??2@YAPAXI@Z ; new函数 add esp, 4 mov [ebp+var_EC], eax ; 这个EC实际上就是new之后返回的一个地址 ; try { mov [ebp+var_4], 0 cmp [ebp+var_EC], 0 ; 判断堆内存是否失败 jz short loc_455B9A mov ecx, [ebp+var_EC] ; 传入的是对象的地址 call sub_450BAD ; 构造函数,返回对象 mov [ebp+var_F4], eax ; 所以F4才是真正的对象 jmp short loc_455BA4 loc_455B9A: ; HANDLE = NULL mov [ebp+var_F4], 0
进入构造函数内部,有如下内容:
完成对象的初始化内容之后,返回了一个对象。
03.参数对象 演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <stdio.h> #include <string.h> class Person {public : Person () { name = NULL ; } Person (const Person& obj) { int len = strlen (obj.name); this ->name = new char [len + sizeof (char )]; strcpy (this ->name, obj.name); } ~Person () { if (name != NULL ) { delete [] name; name = NULL ; } } void setName (const char * name) int len = strlen (name); if (this ->name != NULL ) { delete [] this ->name; } this ->name = new char [len + sizeof (char )]; strcpy (this ->name, name); } public : char * name; }; void show (Person person) printf ("name:%s\n" , person.name); } int main (int argc, char * argv[]) Person person; person.setName ("Hello" ); show (person); return 0 ; }
主要是在show函数调用时,会进行一个拷贝构造:
在类的识别分析那里有一点笔记参考。
析构函数: 01.局部对象 局部对象的析构过程和构造过程差不太多,执行位置不同而已,就不写了
02.堆对象 演示代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <stdio.h> class Person {public : Person () { age = 20 ; } ~Person () { printf ("~Person()\n" ); } int age; }; int main (int argc, char * argv[]) Person *person = new Person (); person->age = 21 ; printf ("%d\n" , person->age); delete person; return 0 ; }
首先Person *person = new Person();跟前面构造函数的堆对象构造所说内容一致。不过多赘述,如图:
接下来person->age = 21;,对应的是这一部分:如下:
对对象内部属性进行一个赋值的操作。
接下来我们来看看后续代码如下:
直接跳入delete函数内部继续分析如下:
主要执行了两个函数操作:
我们进入第一个中可以明显的发现其正是析构函数操作:如下:
我们再来看其第二个操作,如下:
delete释放对象内存